

“High speed,” “minimum latency,” and “ultimate performance” are often used to characterize Apache APISIX. Even when someone asks me about APISIX, my answer always includes “high-performance cloud native API gateway.”
Performance benchmarks (vs. Kong, Envoy) confirm these characteristics are indeed accurate (test yourself).

Tests run for 10 rounds with 5000 unique routes on Standard D8s v3 (8 vCPUs, 32 GiB memory)
But how does APISIX achieve this?
To answer that question, we must look at three things: etcd, hash tables, and radix trees.
In this article, we will look under the hood of APISIX and see what these are and how all of these work together to keep APISIX maintaining peak performance while handling significant traffic.
etcd as the Configuration Center
APISIX uses etcd to store and synchronize configurations.
etcd is designed to work as a key-value store for configurations of large-scale distributed systems. APISIX is intended to be distributed and highly scalable from the ground up, and using etcd over traditional databases facilitates that.
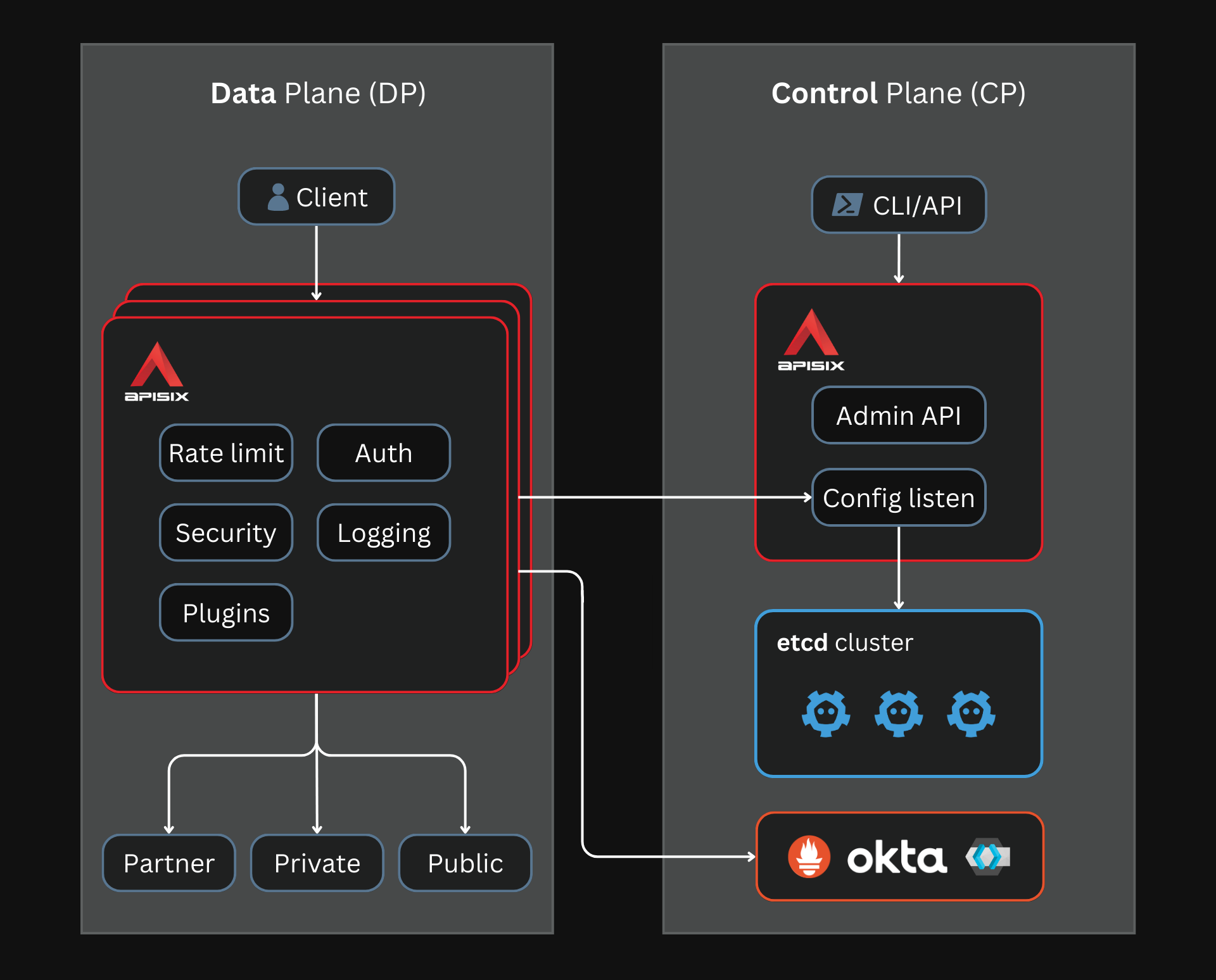
Using an etcd cluster to store and manage APISIX configuration
Another key indispensable feature for API gateways is to be highly available, avoiding downtime and data loss. You can efficiently achieve this by deploying multiple instances of etcd to ensure a fault-tolerant, cloud native architecture.
APISIX can read/write configurations from/to etcd with minimum latency. Changes to the configuration files are notified instantly, allowing APISIX to monitor only the etcd updates instead of polling a database frequently, which can add performance overhead.
This chart summarizes how etcd compares with other databases.
Hash Tables for IP Addresses
IP address-based allowlists/denylists are a common use case for API gateways.
To achieve high performance, APISIX stores the list of IP addresses in a hash table and uses it for matching (O(1)) than iterating through the list (O(N)).
As the number of IP addresses in the list increases, the performance impact of using hash tables for storage and matching becomes apparent.
Under the hood, APISIX uses the lua-resty-ipmatcher library to implement this functionality. The example below shows how the library is used:
local ipmatcher = require("resty.ipmatcher")
local ip = ipmatcher.new({
"162.168.46.72",
"17.172.224.47",
"216.58.32.170",
})
ngx.say(ip:match("17.172.224.47")) -- true
ngx.say(ip:match("176.24.76.126")) -- false
The library uses Lua tables which are hash tables. The IP addresses are hashed and stored as indices in a table, and to search for a given IP address, you just have to index the table and test whether it is nil or not.

To search for an IP address, it first computes the hash (index) and checks its value. If it is non-empty, we have a match. This is done in constant time O(1).
Radix Trees for Routing
Please forgive me for tricking you into a data structures lesson! But hear me out; this is where it gets interesting.
A key area where APISIX optimizes performance is route matching.
APISIX matches a route with a request from its URI, HTTP methods, host, and other information (see router). And this needs to be efficient.
If you have read the previous section, an obvious answer would be to use a hash algorithm. But route matching is tricky because multiple requests can match the same route.
For example, if we have a route /api/*, then both /api/create and /api/destroy must match the route. But this is not possible with a hash algorithm.
Regular expressions can be an alternate solution. Routes can be configured in a regex, and it can match multiple requests without the need to hardcode each request.
If we take our previous example, we can use the regex /api/[A-Za-z0-9]+ to match both /api/create and /api/destroy. More complex regexes could match more complex routes.
But regex is slow! And we know APISIX is fast. So instead, APISIX uses radix trees which are compressed prefix trees (trie) that work really well for fast lookups.
Let’s look at a simple example. Suppose we have the following words:
- romane
- romanus
- romulus
- rubens
- ruber
- rubicon
- rubicundus
A prefix tree would store it like this:

The highlighted traversal shows the word “rubens”
A radix tree optimizes a prefix tree by merging child nodes if a node only has one child node. Our example trie would look like this as a radix tree:

The highlighted traversal still shows the word “rubens”. But the tree looks much smaller!
When you create routes in APISIX, APISIX stores them in these trees.
APISIX can then work flawlessly because the time it takes to match a route only depends on the length of the URI in the request and is independent of the number of routes (O(K), K is the length of the key/URI).
So APISIX will be as quick as it is when matching 10 routes when you first start out and 5000 routes when you scale.
This crude example shows how APISIX can store and match routes using radix trees:
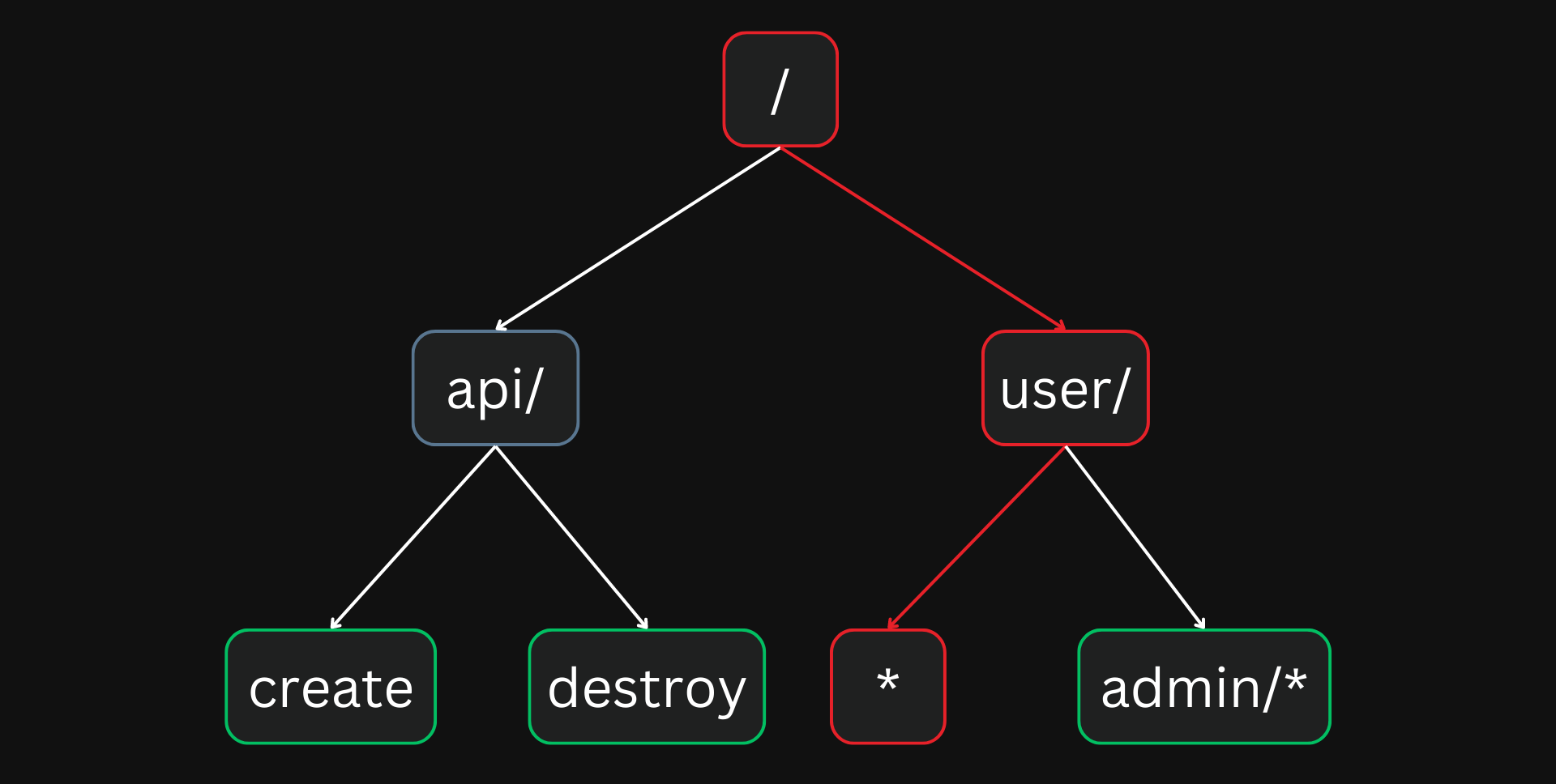
The highlighted traversal shows the route /user/* where the * represents a prefix. So a URI like /user/navendu will match this route. The example code below should give more clarity to these ideas.
APISIX uses the lua-resty-radixtree library, which wraps around rax, a radix tree implementation in C. This improves the performance compared to implementing the library in pure Lua.
The example below shows how the library is used:
local radix = require("resty.radixtree")
local rx = radix.new({
{
paths = { "/api/*action" },
metadata = { "metadata /api/action" }
},
{
paths = { "/user/:name" },
metadata = { "metadata /user/name" },
methods = { "GET" },
},
{
paths = { "/admin/:name" },
metadata = { "metadata /admin/name" },
methods = { "GET", "POST", "PUT" },
filter_fun = function(vars, opts)
return vars["arg_access"] == "admin"
end
}
})
local opts = {
matched = {}
}
-- matches the first route
ngx.say(rx:match("/api/create", opts)) -- metadata /api/action
ngx.say("action: ", opts.matched.action) -- action: create
ngx.say(rx:match("/api/destroy", opts)) -- metadata /api/action
ngx.say("action: ", opts.matched.action) -- action: destroy
local opts = {
method = "GET",
matched = {}
}
-- matches the second route
ngx.say(rx:match("/user/bobur", opts)) -- metadata /user/name
ngx.say("name: ", opts.matched.name) -- name: bobur
local opts = {
method = "POST",
var = ngx.var,
matched = {}
}
-- matches the third route
-- the value for `arg_access` is obtained from `ngx.var`
ngx.say(rx:match("/admin/nicolas", opts)) -- metadata /admin/name
ngx.say("admin name: ", opts.matched.name) -- admin name: nicolas
The ability to manage a large number of routes efficiently has made APISIX the API gateway of choice for many large-scale projects.
Look under the Hood
There is only so much I can explain about the inner workings of APISIX in one article.
But the best part is that the libraries mentioned here and Apache APISIX are entirely open source, meaning you can look under the hood and modify things yourself.
And if you can improve APISIX to get that final bit of performance, you can contribute the changes back to the project and let everyone benefit from your work.