

I recently found articles from the past few years about companies migrating away from Nginx. Some of these migrations are to other reverse proxies like Envoy, while others choose to build their own in-house solutions.
Although these migrations seem reasonable, it does not necessarily mean the grass will always be greener. There is a lot of nuance in the reasons behind such migrations, and it might not translate well across the board.
It also does not mean Nginx has no shortcomings. It definitely does. But despite this, Nginx does many things very well and is probably a fine choice as a capable web server, reverse proxy, load balancer, and more.
Worker Process Model
A key enabling factor of Nginx is its worker process model. By default, Nginx spins up one worker process per CPU core.
Connections to Nginx are load-balanced across these workers. And each of these workers can serve thousands of connections. The worker process never leaves the CPU as it needs to continuously parse the data stream in the listening port.
These worker processes are created by a master process, which also does privileged operations like reading the configuration and binding to listening ports. The process model can be summarized as below:
- Nginx starts a master process to perform privileged operations. The master process is also responsible for creating child processes.
- The cache loader process runs at the start to load the disk-based cache into memory and then exits.
- The cache manager process clears entries from the disk caches to keep them within the set limits.
- Worker processes then handle the network connections, from clients to Nginx and from Nginx to the upstream services, while reading and writing content to the disk.
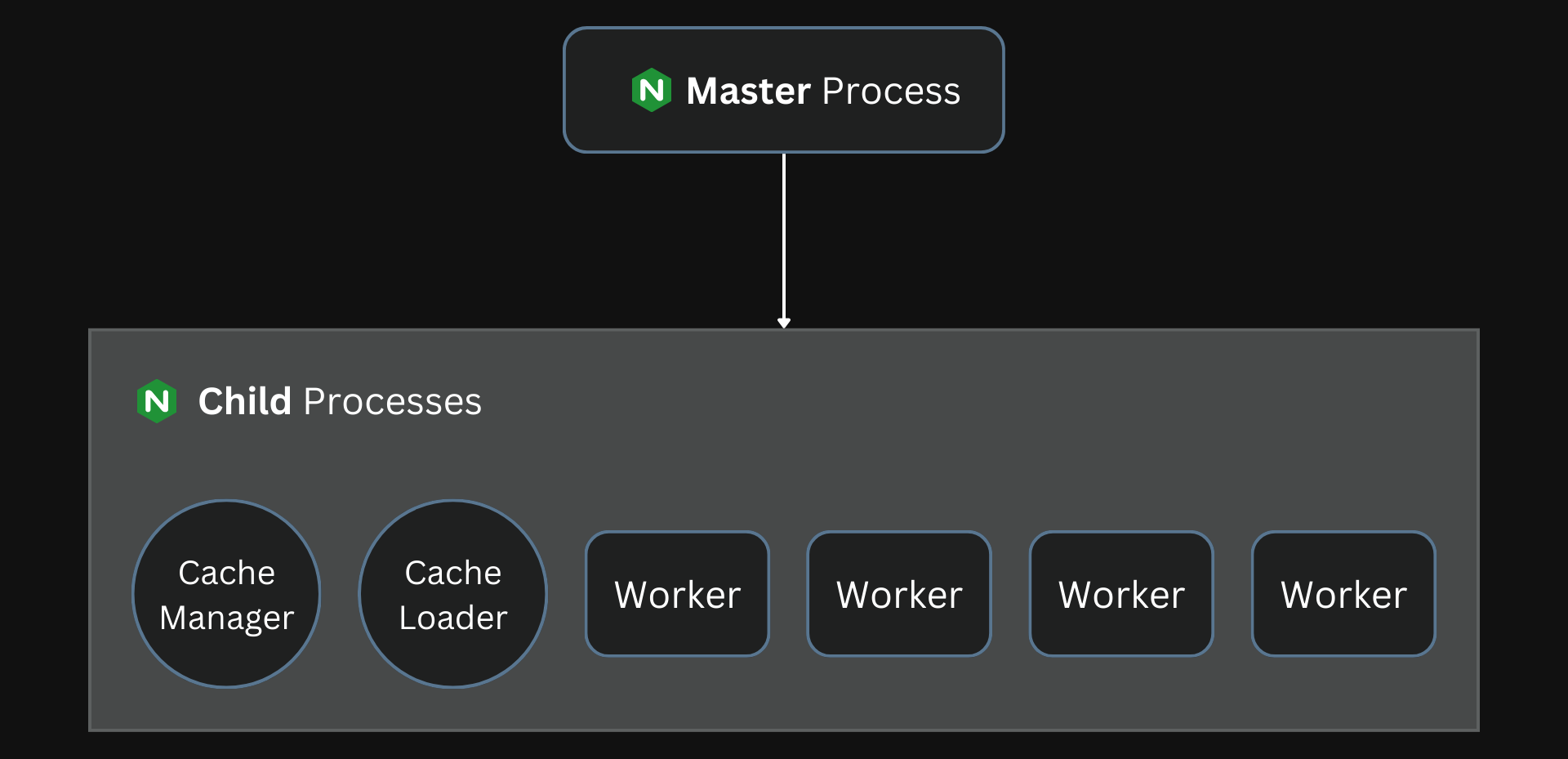
If the CPU has four cores, Nginx creates four worker processes by default.
Nginx follows an event-driven model where the worker processes wait for events on the listening ports. A new incoming connection initiates an event.
When the worker is done with a request, it does not wait for a response from the client and moves on to the subsequent request in the queue.
Non-blocking at Scale
When Nginx was first released, most other web servers did not follow a similar model and spun up a new process/thread per request, restricting each worker to process only one connection at a time. While this was convenient, it was ineffective in utilizing resources.
On the other hand, the event-driven model allows Nginx to be non-blocking while handling thousands of simultaneous connections.
The worker creates a new connection socket on events on the listen socket. The worker then responds promptly to events on the connection socket.
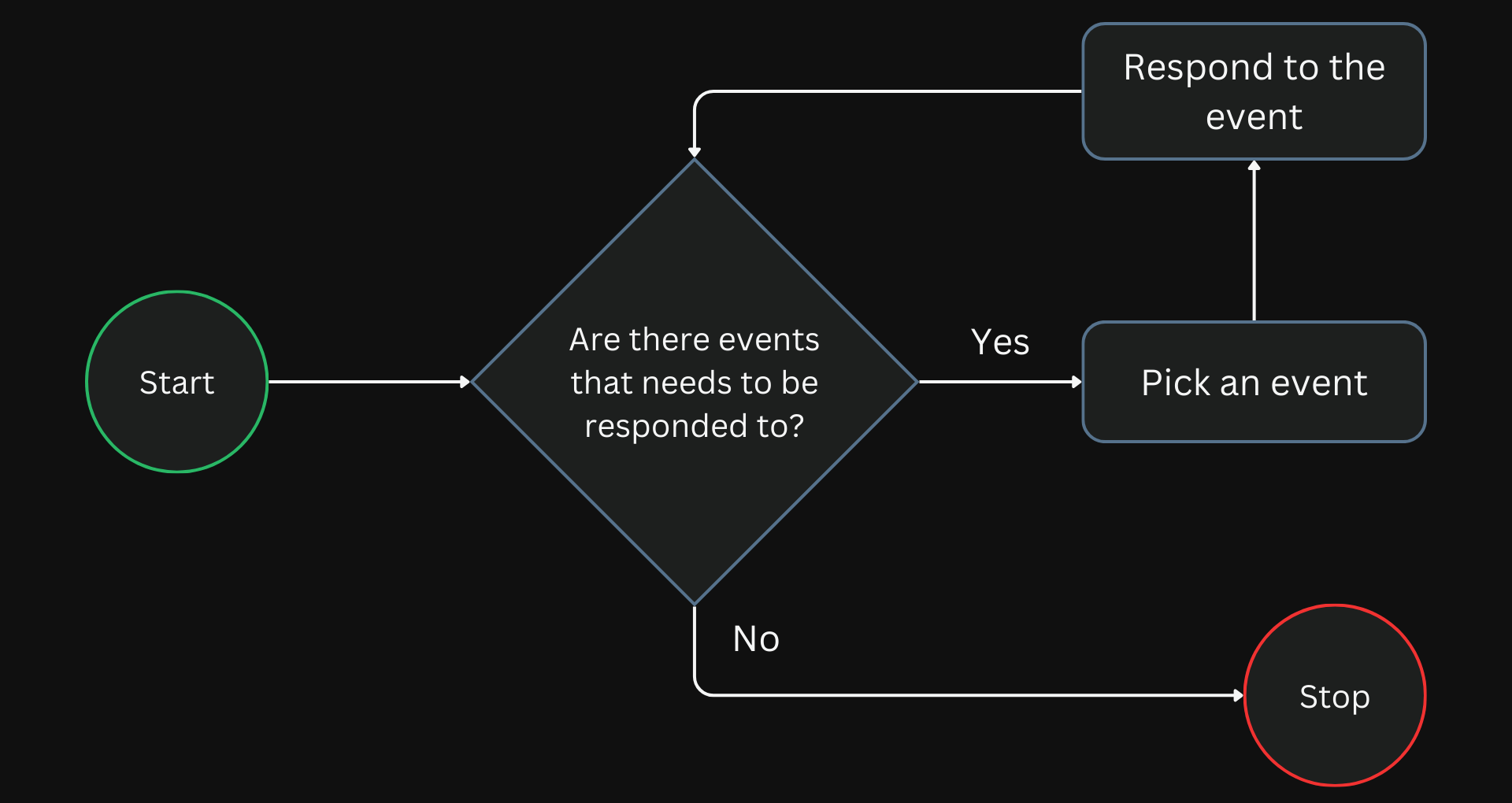
The workers do all the processing over a simple loop. Sourced from Thread Pools in NGINX Boost Performance 9x!
Nginx’s ability to scale is also evident in other areas. For example, when updating Nginx’s configuration, existing worker processes exit gracefully after serving existing requests while the master process starts new workers with the new configuration.
This is essential in systems that serve significant traffic to avoid downtime. The cost of doing this is also slim and results only in a tiny spike in CPU usage during the configuration change.
Although Nginx is designed to be non-blocking, it won’t hold true in scenarios where processing a request takes a lot of time, like reading data from a disk.
In such scenarios, even though other requests in the queue might not require blocking processes, they are forced to wait.
Marginal Overheads
There is very little overhead in adding a new connection in Nginx. Each new connection just creates a new file descriptor and consumes only a tiny amount of additional memory.
And since each worker is pinned to a CPU, there is also less context switching necessary as the same worker can handle multiple requests. i.e., there is no need to load processes on and off between the CPU and memory frequently.
In a multiprocess model, context switching will be frequent and limit scalability.
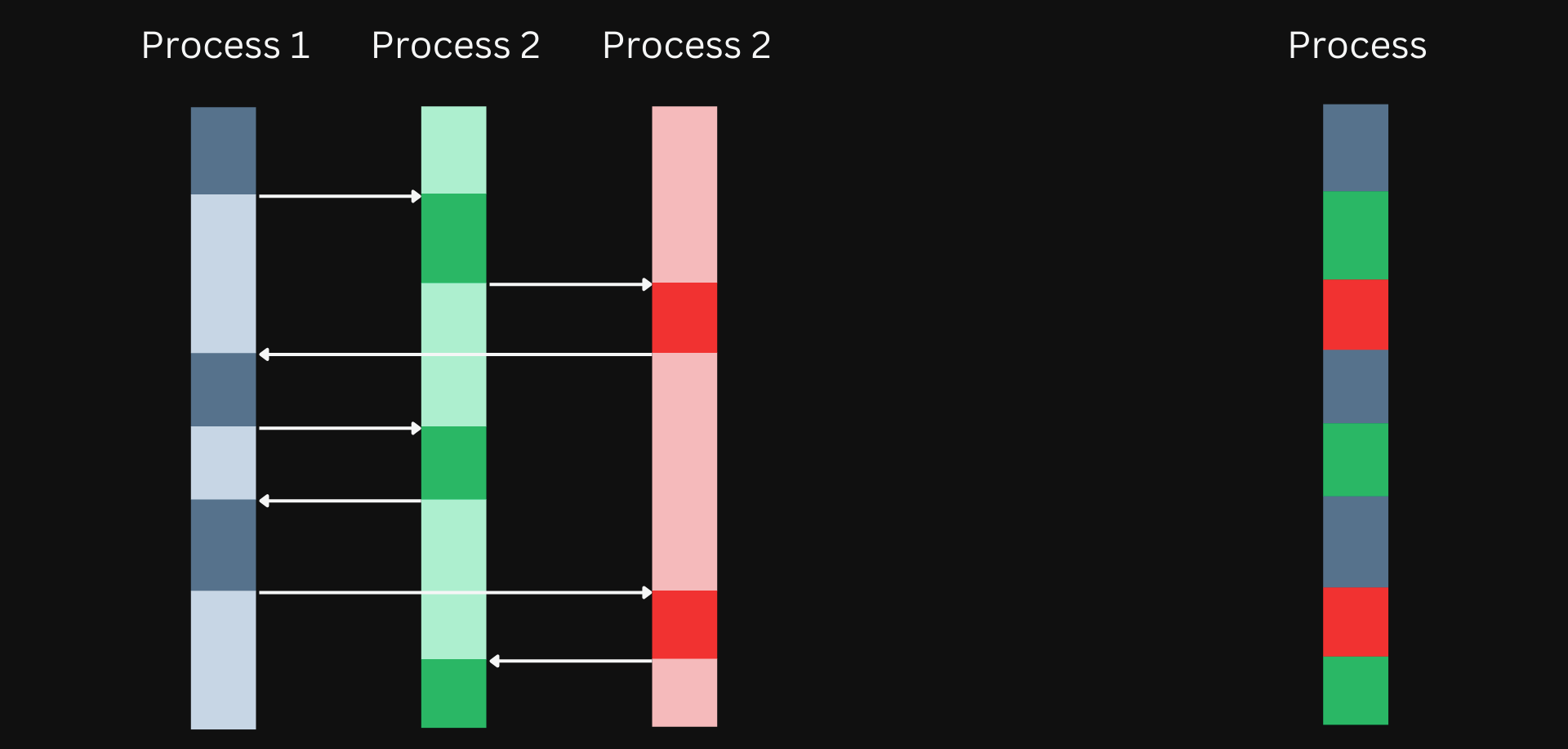
In a multiprocess model each of the process is frequently loaded on and off between the CPU and memory.
Redundant Connections
You can configure Nginx to hold open the connections to the upstream even after completing a request. If another request needs to be made to the same upstream, Nginx can reuse this connection instead of establishing a new connection.
But, a significant drawback of Nginx is that even though we can set up connections to be reused, different workers will still end up establishing their own connections to the same upstream. This is difficult to solve because sharing the connection pool across multiple processes is difficult.
So, a request being processed by a worker must pick from existing connections established in the same worker process or create a new one even though they might already exist in other processes.
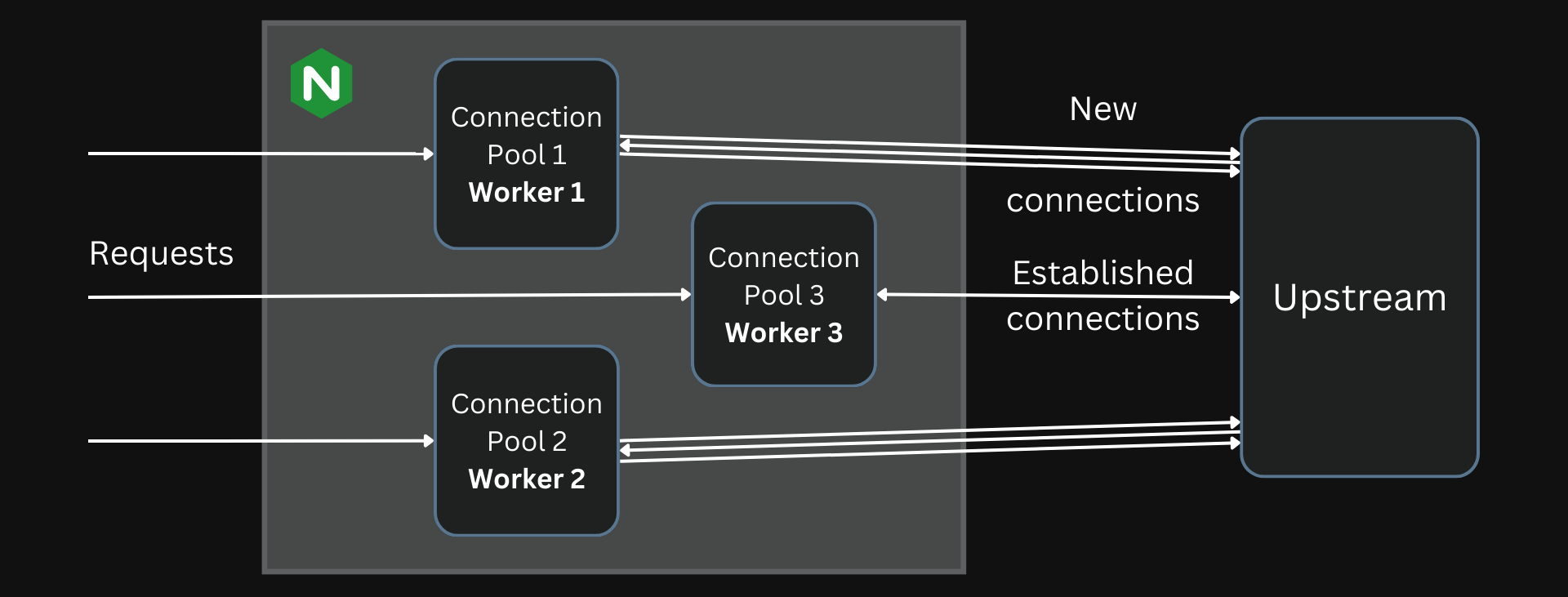
Each worker has its own connection pool which cannot be shared easily with the other workers.
Multiprocessing vs Multithreading
This redundancy tilts the scales in favor of a multithreading architecture over the worker process model used in Nginx.
Multithreading allows each thread to share the same connection pool since they share a common memory address space. This eliminates the need to spin up and maintain new connections for each worker.
Connections are shared across workers by using a multithreaded architecture.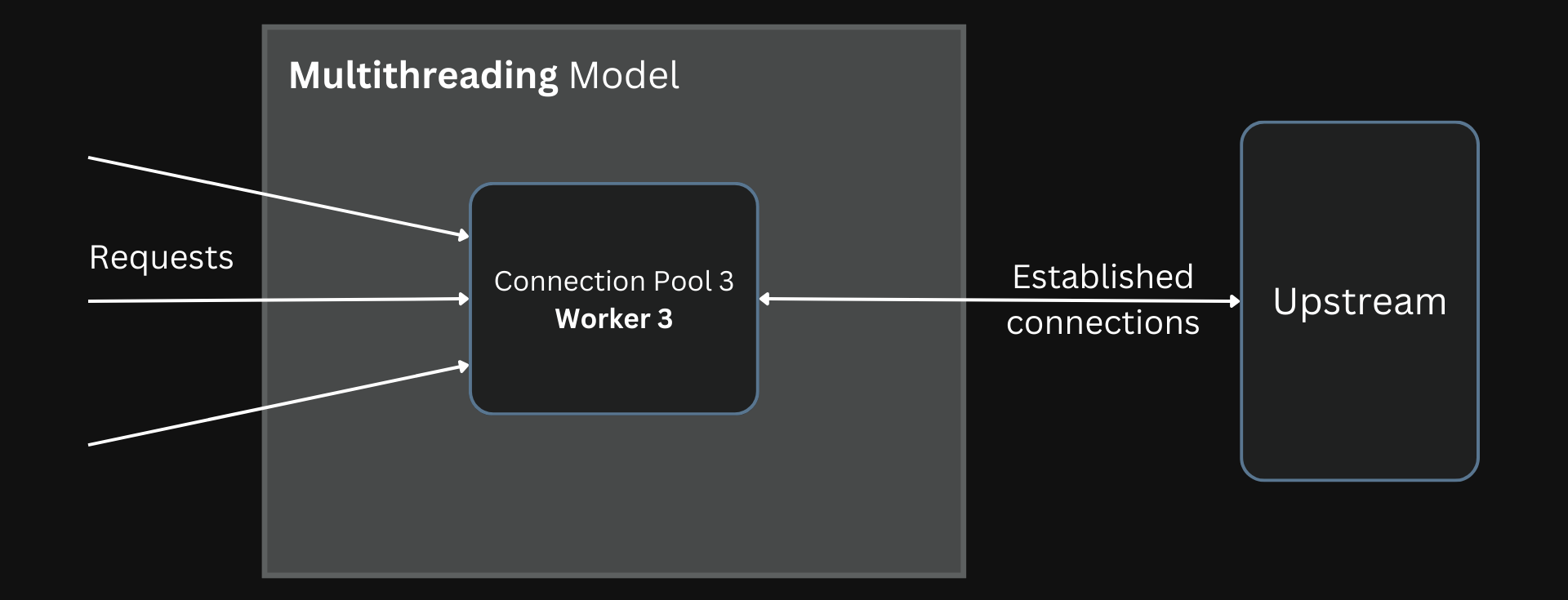
A multiprocess model is immune to such a problem because each process runs in its isolated space. Still, multithreading is more easy to achieve right now with programming languages like Rust.
Load Heavy Workers
The multiple worker processes in Nginx listen to just a single listen socket. When a request arrives, an available worker picks it up and processes it.
Although this seems like an acceptable way to handle things, it disproportionately burdens the most busy worker because of how this works in Linux.
Linux load balances in a last-in-first-out way where the worker that just completed processing a request is put back on top of the list. Then, the subsequent request is assigned to this worker even though it has just finished working.
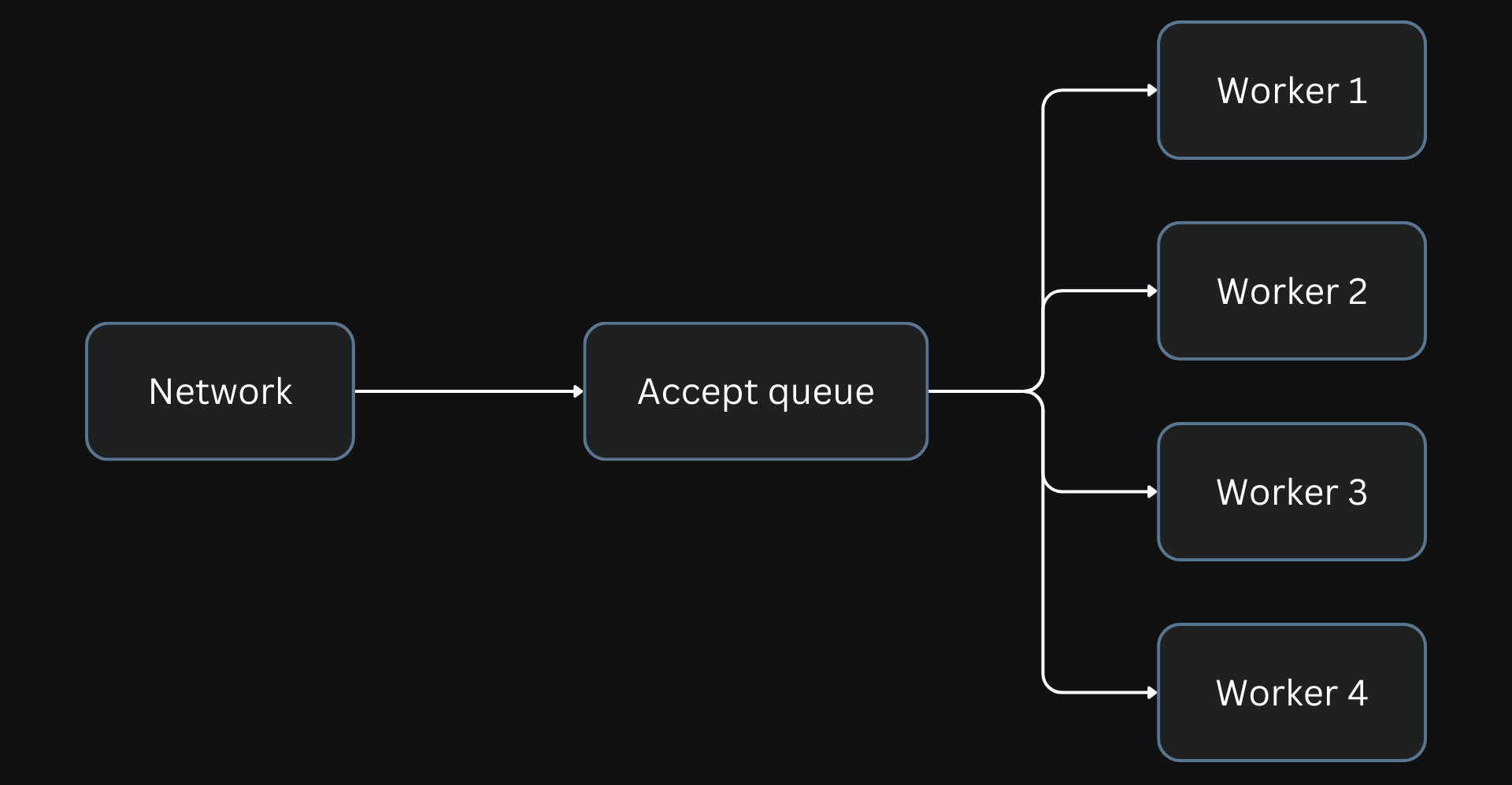
In the epoll method for processing connections, the worker added last to the queue will get the new connection.
Imperfect Solutions
A different approach for processing connections can offload these heavy workers.
Nginx allows socket sharding where each worker can have a separate listen socket. In this model, the incoming connections are split into the different accept queues of each worker.
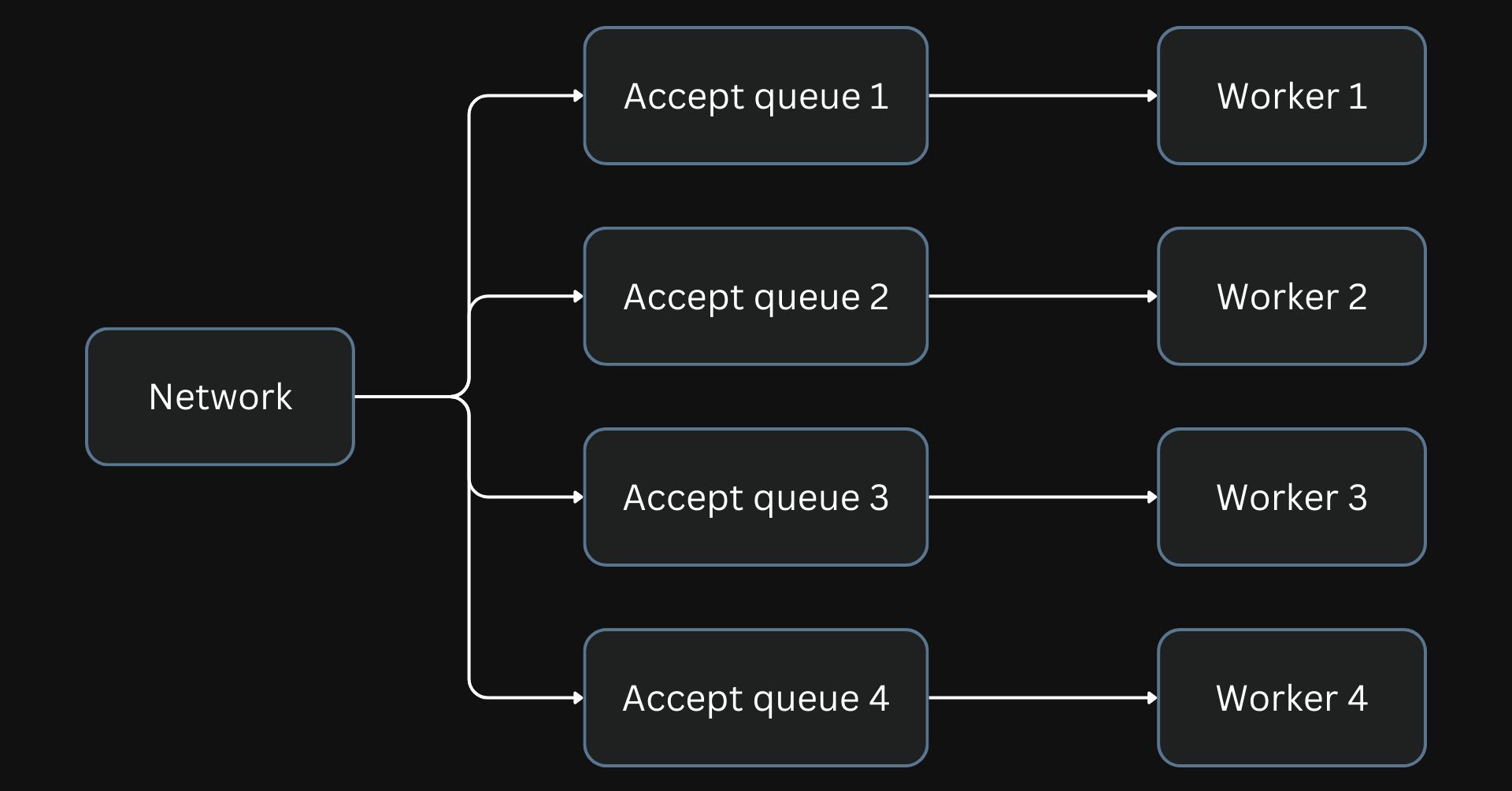
Better load distribution can be achieved by using multiple accept queues.
This can be enabled by configuring the SO_REUSEPORT socket option.
Since the accept queues are not shared, Linux distributes the incoming connections more evenly across the workers, and no single worker is disproportionately loaded.
However, this solution brings another problem. If a worker process is blocked, all connections in its accept queue will be blocked, even if they are light and non-blocking. This will increase the overall latency of the entire system.
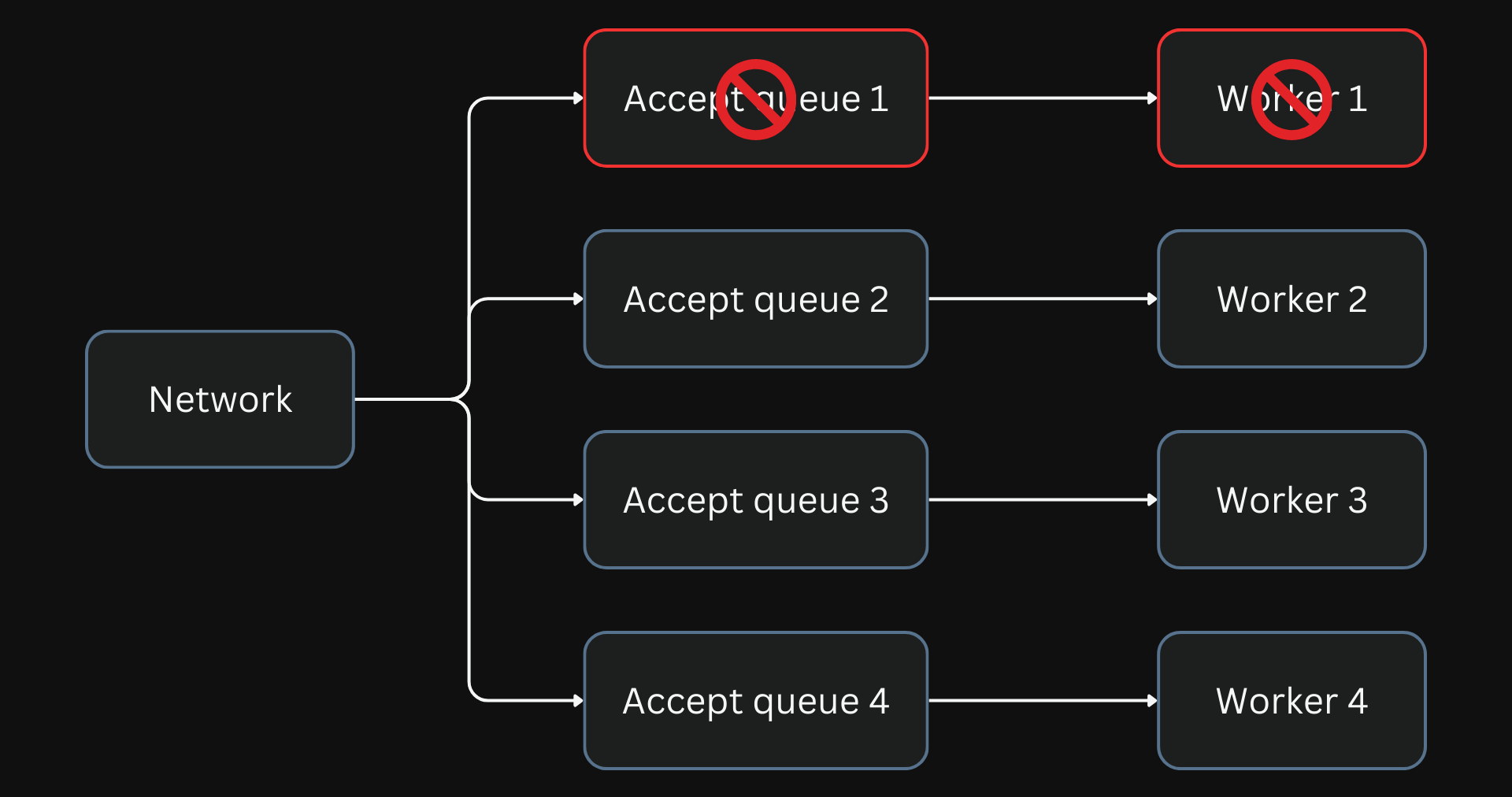
One blocked process blocks the entire connections in the accept queue of the worker process. But the network continues to add more connections to the queue.
Other solutions that emerged over time, like using thread pools to perform blocking operations without affecting other requests in the queue, are good. Nginx can offload long operations (all read(), sendfile(), and aio_write operations) to a thread pool queue, and any free thread can take it for processing.
But in most scenarios, you will be fine without thread pools if your machines have reasonable memory and don’t have to load large data sets from disk into memory. You can extract good performance with Nginx’s default optimizations and the operating system’s features like caching.
Abstracting Network Connections
There is a small subset of use cases where every ounce of performance improvements might be necessary. For the rest of us, Nginx is an abstraction of the underlying network.
We care more about building applications that are functional and performant without having to spend resources building custom solutions when Nginx would work out of the box.
Even abstractions on top of Nginx make it much easier for most developers to build and configure reverse proxies and load balancers. For example, Apache APISIX is built on top of OpenResty, a modified Nginx build.
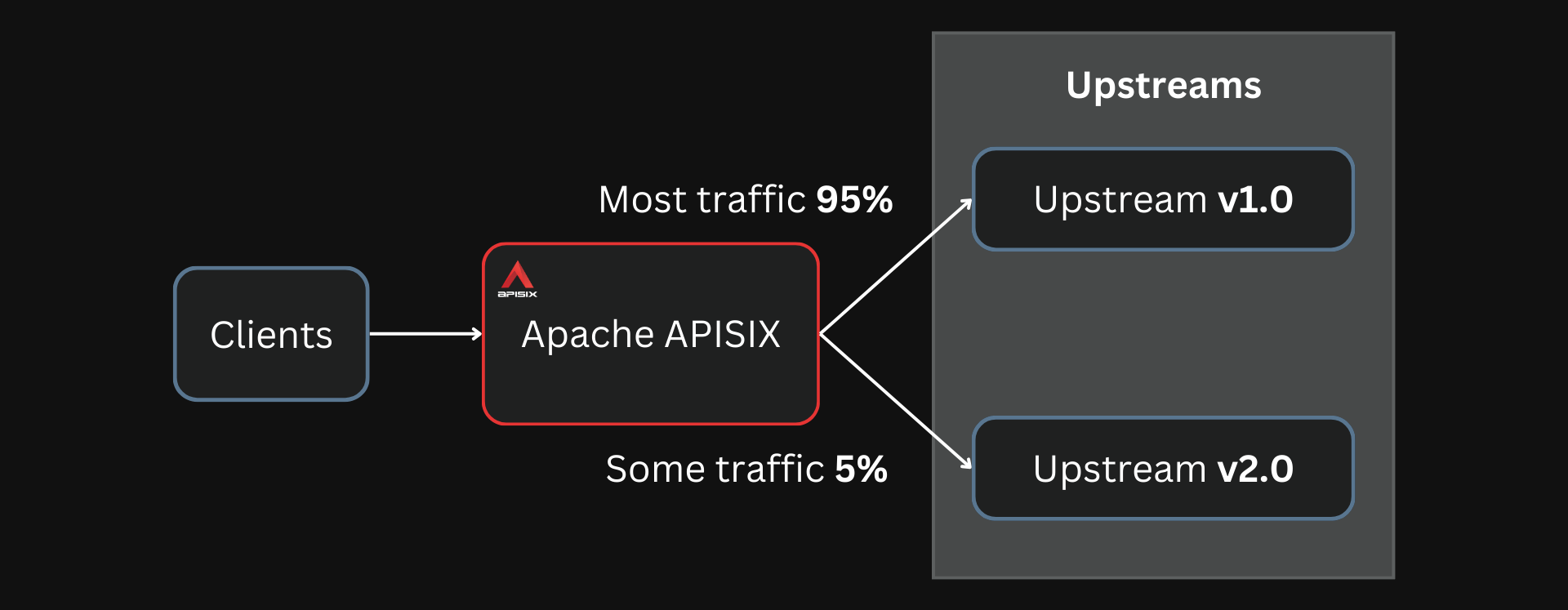
You can easily configure Apache APISIX to set up canary deployments while deploying new versions of your applications.
You can use tools like Apache APISIX to route traffic, configure authentication, set up monitoring, and more without worrying about the details underneath.
Probably Fine
While there are situations where it might be reasonable to move away from Nginx and use something better tailored to your specific need, it might not be something that everybody should be doing.
Nginx, its vast ecosystem, large community, and battle-tested stability can easily be your drop-in solution.
In other words, Nginx is probably fine.
See the discussion on Reddit.